Letenyei László - Vedres Balázs: Kapcsolatháló e-kurzus
(Az első hat alkalmat Letenyei László, a második hatot Vedres Balázs tartja).
Letenyei László: Kapcsolatháló elemző ABC (az első hat alkalom tematikája)
Az elektronikus kézirat a Településkutatás c. könyv átdolgozott részleteit tartalmazza: Letenyei László: Településkutatás. Ráció Kiadó, 2005. A teljes verzió megrendelhető a kiadónál: raci@racio.hu de sajnos, elég drága, a könyvesboltokban 6000 Ft a két kötet. A kiadónál, gondolom, legalább 10%-kal olcsóbb.
A kurzushoz nem tarozik irodalom, az érdeklődők figyelmébe elsősorban Kürtösi Zsófia és Szántó Zoltán írását ajánlom. (In: LL (szerk): Településkutatás szöveggyűjtemény. Ráció Kiadó, 2005.) illetve folyamatosan bővülő könyvtárunkat: http://www.socialnetwork.hu/cikkek/cikkek.htm
A példaként bemutatott UCINET adatbázis itt letölthető.
1. lecke: Ego háló és kapcsolatháló (2005. szeptember 28.)
Gyakorlat: UCINET és EGONET programcsomagok letöltése és otthoni telepítése.
Házi feladat: Projekt-ötletek készítése és elküldése a listára.
Figyelem: a 2. leckéhez le kell tölteni és telepíteni a UCINET 6.x beta verziót!
Aki még nem tette, itt letöltheti: www.analytictech.com
2. lecke: Kapcsolatháló adatbázis összeállítása és rajzolása (2005. október 6.)
Gyakorlat: adatbázis szerkesztés az UCINET-ben, megjelenítés Netdraw-val.
Házi feladat: Saját adatbázis szerkesztése, megjelenítése. Házi feladatként a rajzokat várjuk, minél kisebb méretben, azaz lehetőleg JPG kiterjesztéssel.
3. lecke: Vizualizáció (2005. október 13.)
Gyakorlat: gráf rajzolása az UCINET alatt Netdraw-val, Mage-dzsel, Pajekkel. Pontok mérete „közöttiség” attribútum szerint. Klikkek, hidak meghatározása
Házi feladat: kapott adatbázis megrajzoltatása különböző programokkal. A gráf értelmezése, elemzések nélkül, „ránézéses” módszerrel..
4. lecke: Sűrűség. (2005. október 20.)
Gyakorlat: kapott adatbázison hálózati sűrűség számítása és a különböző mérőszámok értelmezése az UCINET-ben.
Házi feladat: saját adatbázison sűrűség mérőszámok számítása és értelmezése.
5. lecke: Központiság. Október 27.
Gyakorlat: kapott adatbázison a központiság néhány mérőszáma és azok értelmezése az UCINET-ben.
Házi feladat: kapott vagy saját adatbázison sűrűség mérőszámok számítása és értelmezése.
6. lecke: Strukturális ekvivalencia. November 3.
Gyakorlat: strukturálisan ekvivalens blokkok beazonosítása egy adatbázisban.
Házi feladat: kapott adatbázison CONCOR elemzés lefuttatása és értelmezése.
A kurzus utáni első továbblépésként elsősorban a következő kézikönyvet ajánlom az érdeklődők figyelmébe:
http://faculty.ucr.edu/~hanneman/nettext/
Ez az ABC egy kalauz kíván lenni a módszertannal ismerkedő kutatók részére. Célja, hogy átsegítse az e-kurzus résztvevőit a kezdeti lépéseken, melyek segítség nélkül meglehetősen nehezek és fárasztóak lennének, és eljuttassa addig a pontig, ahonnan már egyszerűbb az önálló továbblépés. Az ABC az alapoktól kezd, és a lehető legegyszerűbb formában mutat be néhány alapvető elemzési technikát.
1. Az első kérdés: kapcsolati tőke vagy kapcsolatháló elemzés
A kutatás tervezés kulcsfogalmai a következők:
Témaválasztás
Mintaválasztás kapcsolati tőke elemzés esetén
Minél teljesebb körű vizsgálat kapcsolatháló elemzés esetén
Kapcsolati tőke elemzések
Kapcsolatháló elemzés
Mint minden módszertan követésekor, a kapcsolatháló elemzés során is fontos, hogy a kutató ne a mindenkori módszertani divatokra, hanem elsősorban a téma sajátos adottságaira, tényleges információszükségletére legyen tekintettel a témaválasztáskor.
A kutatás elején a kutatónak legelőször azt kell eldöntenie, hogy kapcsolatháló, vagy kapcsolati tőke kutatást szeretne-e folytatni. Bár vannak olyan példák, sőt, az Egonet, vagy a Siena programcsomagok révén kész algoritmusok is léteznek, amelyek összekötik a kétfajta elemzési eljárást, mégis célszerűbb, ha a kutató határozottan az egyik, vagy a másik fajta kutatási irány mellett teszi le a voksát. Ha a kapcsolati tőke kutatást választjuk, és egy nagy sokaságból merített reprezentatív mintát elemzünk, akkor általában már nem nyerhetünk teljes hálóra vonatkozó adatokat. A kétfajta kutatási irányt csak úgy lehet összeegyeztetni, ha összefüggő hálóból indulunk ki, ez esetben viszont az ego háló elemzés sokszor nem mond többet, mint ami a háló struktúrájából egyébként is látszik.
Kapcsolati tőke elemzés esetén az adatokból az analitikus elemzésekhez hasonló módon készíthetünk adatbázist, és „szokásos” módon elemezhetünk, SPSS-szel, vagy más programcsomagokkal.
Kapcsolatháló elemzés esetén eltérő szemlélettel, másfajta adatokból indulunk ki, és sajátos elemzési technikákat valósítunk meg. A további pontok csak a háló elemzéssel foglalkoznak.
2. Adatgyűjtési technikák
megfontolnivalók:
Sok szereplőt kutassunk, vagy keveset?
A vizsgálatba bevontak körének meghatározása
A mintavétel esélye és veszélyei
Kvalitatív adatgyűjtési technikák
Kvantitatív adatgyűjtési technikák
Dichotóm változók
A kapcsolatháló elemzés egyik kulcskérdése, hogy a kutató hogyan határozza meg azoknak a szereplőknek a körét, amelyekkel foglalkozni akar. Szerencsés helyzetben a vizsgálat tárgya egy megszámlálható és lehetőleg nem túl nagy méretű sokaság. Településkutatás során ilyen „átlátható” sokság lehet például egy kistérség vagy akár egy megye települései, vagy egy nagyobb település városrészei. Sok esetben viszont a kutatás kifejezetten nagy sokaságokra vonatkozik, például egy kistérség gazdasági szereplőire (vállalkozások, cégek, nonprofit szervezetek összessége). Bár a sokaság nem végtelen, nehezen lehetne minden egyes szereplőről adatot gyűjteni, illetve egy ilyen adatgyűjtés nem lenne elég mély, csak formális adatokat tartalmazna, tehát alkalmasint amit nyerünk a HÉVen, elveszítjük a MÁVon.
Sokan azt gondolják, hogy a kapcsolatháló elemzések azért foglalkoznak előszeretettel kisebb sokasággal, mert a módszertan nem alkalmas nagy adattömeg kezelésére. A valóságban mind az elemző algoritmusok, mind a rendelkezésre álló szoftverek képesek tetszőleges méretű adatbázist kezelni, és adekvát kutatási kérdések esetében vannak is példák rendkívül nagy, akár több millió vagy milliárd elemű hálók vizsgálatára. A kisebb hálók vizsgálatát a társadalmi kérdések esetében inkább az adatgyűjtés fenti sajátságai és elméleti megfontolások indokolják. Természetesen elképzelhetők olyan kutatási kérdések is, ahol érdemes nagy sokasággal foglalkozni. Ha például valaki a testvérvárosi kapcsolatokat akarja kutatni, akkor akár egész Európa valamennyi településére vonatkozóan is viszonylag könnyen jut megbízható adatokhoz az Internetről, és nem kell feltétlenül leszűkítenie a kutatását egyes országokra, vagy a nagyobb városokra.
Nagyobb sokaság esetében tehát – példánkban: cégvilág, vagy egy nagyobb régió települései – a kutató általában arra kényszerül, hogy valahol meghúzza a kutatása határait (vesd össze a www.socialnetwork.hu oldalon Kürtösi Zsófia írásával). Településkutatás során jellemzően a következő szempontok alapján szokták ezt megtenni:
- legjelentősebb szereplők (például: az első 500 legnagyobb árbevételű cég, vagy 1000 lakos feletti települések),
- egy kiválasztott, szorosan összetartozó alcsoport, melynek tagjai egy csoportba tartozónak tartják magukat, és ezt formálisan vagy informálisan kifejezik (például kistérségi önkormányzati szövetség tagjai, vagy egy gazdasági kartell)
- egy központ köré szerveződő, hasonló helyzetű (de egymással nem feltétlenül kapcsolatban álló) blokk, például egy nagyvállalat és beszállítói, vagy egy agglomerációs övezet
- hólabda módszer: a választott sokaság néhány tetszőlegesen választott tagjától kiindulva, az ő kapcsolataikon továbbhaladva addig folytatjuk a kutatást, amíg a kapcsolati szálak összeérnek. Ezzel biztosítjuk, hogy a legjelentősebb szereplők benne legyenek a vizsgálatban, ugyanakkor eljuthatunk a kapcsolatháló periférikus helyzetű szereplőjéhez is. A módszer veszélye, hogy egész blokkok maradhatnak ki a vizsgálatból, központi szereplőjükkel együtt.
A fentieken kívül természetesen további szempontok is elképzelhetők a vizsgálandó sokaság lehatárolására.
A mintavétel, mint korábban hangsúlyoztuk, alapvetően az ego háló kutatások eszköze. Ennek ellenére egy reprezentatív mintából származó adatok is árulkodhatnak a teljes háló néhány sajátságáról, becsülhető például a kapcsolatháló sűrűsége. Az ilyen becslésekkel azonban óvatosan kell bánni. Barabási Albert László kutatásai épp arra világítottak rá, hogy a skálafüggetlen hálóknak néhány, sok kapcsolattal rendelkező pont a központja, melyek kis valószínűséggel kerülnek be egy reprezentatív mintába, viszont meghatározók a háló struktúráját tekintve (a témával kapcsolatban lásd a recenzót).
A mintavétel módja nagyban befolyásolja az adatgyűjtés eszközeit. Kisebb sokaságnál általában a kvalitatív technikák adekvátabbak, segítségükkel a kapcsolatok megléte vagy épp’ hiánya mellett kideríthető azok tényleges tartalma, kölcsönös jellege, stb. Településkutatás során, intézményközi kapcsolatok (például helyi önkormányzatok, nonprofit szervezetek, stb.) vizsgálatakor az interjúsorozat gyakran hoz meglepő eredményeket. Sok együttműködés csak szóbeli megegyezésen, pontosabban egy hagyományos bizalmi kapcsolaton alapul, de ennek ellenkezőjére is találhatunk példát, hogy a két település vagy a két polgármester közötti rossz viszony miatt nem lehet tartalommal megtölteni az írásos megállapodásokat. A résztvevő megfigyelés is sokszor lehet hasznos eszköz, például településközi vagy városrészek közti forgalom vizsgálatakor érdemes megfigyelni, merre mennek reggel és este az emberek, velük együtt bejárni a jellemző útvonalakat, stb.
Nagyobb sokaságnál általában nincs lehetőség puha adatgyűjtési technikákra, a kérdőív, vagy valamilyen nyilvános adatbázis felhasználása lehet járható út. Kérdőív esetében nem érdemes a kapcsolat tartalmával és mélységével foglalkozni. Az olyan kérdések, mint a „Mennyire érzi közel önhöz a rokonait?” jellemzően sutára sikerednek. A „Kik a legfontosabb üzleti partnerei/vevői?” kérdésre az esetek többségében ad hoc, megbízhatatlan válaszokat kapunk. A puha kérdéseket ezúttal is bízzuk inkább a puha technikákra: jobb egy világos és egyszerű kérdőív mellett egy kiegészítő, de szűkebb körű interjúsorozatot folytatni, mint a kérdőívet puhítani. A kérdőív kérdései legyenek világosak és félreérthetetlenek, lehetőség szerint csak arra kérdezzenek rá, hogy van-e kapcsolat az adott szereplővel a vizsgált szempont szerint, vagy nincs. Ha mások által gyűjtött adatokból indulunk ki (pl. cégbírósági adatok, sajtóhírek, szervezeti tagságok), hasonlóan „egyszerű” adatokat kell keresnünk.
A „kemény” technikák révén is vizsgálhatók érzékeny kérdések. Az interlock kutatások például azzal foglalkoznak, hogy kik jelentenek személyükben kapcsolatot az intézmények között, azaz vannak-e olyan emberek, akik egy politikai csoport képviselőjeként több cég felügyelő bizottságának is tagjai, bár a szervezetek között nincs formális kapcsolat. A települések vagy intézmények közötti potenciális (kölcsönösen előnyös) együttműködések, a megkötött keretegyezmények és a tényleges együttműködések egybevetése szintén érdekes eredményeket hozhat.
Már adatfelvételkor tekintettel kell lennünk a későbbi elemzési technikákra, és az interpretációra. Általában akkor elemezhető és interpretálható könnyen az eredmény, ha az adatok dichotóm (kétértékű) változó azaz 0 vagy 1 értéket vesznek fel. Az 1 értelme, hogy van kapcsolat a két szereplő között, a 0 pedig, hogy nincs. Sok elemző eljárás értékét befolyásolják a (0-1)-től eltérő értékek. Ez néhány esetben elemzési többletet jelenthet, legtöbbször viszont érvénytelen eredményekhez vezet. Jelen kötet csak dichotóm változókkal végzett elemzések bemutatására vállalkozik, elsősorban nem terjedelmi okok miatt, hanem azért, mert gyakorlatban ritkán éri meg mást használni. A (0-1)-től eltérő értékeket, például negatív számokat sokan a kapcsolat erősségének vagy irányának jelölésére szeretnék használni. A kapcsolat erőssége többnyire nehezen definiálható, ordinális skálán értékelhető fogalom, statisztikai elemzésbe nem érdemes bevonni. Ha a kapcsolat erősségét a rétegezettséggel definiáljuk (hány különböző minőségű kapcsolatot ápol egymással két szereplő, például egyszerre barát és kollega) akkor javasolt inkább a különböző szempontok szerint egy-egy újabb mátrixot készíteni, és mindegyikben dichotóm változókkal jelölni, hogy van-e vagy nincs kapcsolat. Ha a kapcsolat irányát akarjuk jelölni, akkor ugyanabban a mátrixban a főátló alatti vagy feletti értékeket kell kitölteni, aszimmetrikus módon. Összességében tehát az adatgyűjtés során a kapcsolat meglétét kell kutatni, a kapcsolat mélységét és tartalmát viszont inkább kvalitatív módon érdemes vizsgálni, és leíró jelleggel, elemzés nélkül interpretálni.
A következő pontok megírásánál arra voltunk tekintettel, hogy a kapcsolatháló elemzésben egészen járatlan kutató a legelső lépésektől kezdhesse az ismerkedést az adatbázis összeállításával és az elemzéssel. Az egyszerűség kedvéért a példákat a kapcsolatháló elemzésben jelenleg legelterjedtebb programcsomag, a Ucinet 6 (Beta, azaz kísérleti) verzióján mutatjuk be. Az ismerkedést megkönnyíti, ha az olvasó otthon letölti magának a programcsomagot – a mindenkori kísérleti verzió ingyen hozzáférhető – és úgy követi a lépéseket.
Az adatbázis összeállításánál felmerülő legfontosabb kérdések a következők:
Adatbázis tervezése
Keret fájl elkészítése
A kapcsolatok értelme
Szimmetrikus és aszimmetrikus mátrix
Sor, oszlop
Adatbevitel
A leendő adatbázis kerettáblája már akkor felvázolható, amikor meghatároztuk a szereplőket, de még mielőtt elkezdenénk adatokat gyűjteni.
A kapcsolatháló adatbázis kialakításánál legtöbb esetben egy kvadratikus (négyzetes) mátrix kialakítására kell törekedni. Kvadratikus mátrixunk sorai és oszlopai ugyanazokra a szereplőkre vonatkozzanak, a mátrix értékei pedig a köztük levő kapcsolatot mutassák. A mátrix elemei közötti kapcsolat a sorból mutat az oszlop felé.
Elképzelhetők olyan vizsgálatok, mikor nem az összes kapcsolat érdekel bennünket, hanem csak néhány meghatározott ponthoz való kapcsolódás (néhány kiemelt hálózati pont felé irányuló kapcsolat). Ilyenkor néhány oszlopot (vagy néhány kivétellel az összes oszlopot) el lehet hagyni. Ez azonban gyakorlatlan kutatóknak nem javasolt, mert bizonyos elemzési algoritmusok csak n*n-es, azaz kvadratikus mátrixokon futnak, vagy csak azokra adnak érvényes eredményt. A kezdő kutatók készítsenek inkább n*n-es adatmátrixot, és legfeljebb bizonyos oszlopokat vagy sorokat töltsenek fel 0-val.
Az adattábla első sora és első oszlopa egyaránt az első elemre vonatkozik. Értelemszerűen az első sor és oszlop közötti kapcsolat (önmagával való kapcsolat) nem értelmezendő információ, ezért ez 0 értéket kap. Mivel ez igaz a 2. szereplő önmagával való kapcsolatra is, a mátrix főátlója nullákból áll. Összességében a mátrix kerettáblája így néz ki:
|
|
1 |
2 |
... |
n |
|
1 |
0 |
|
|
|
|
2 |
|
0 |
|
|
|
... |
|
|
0 |
|
|
n |
|
|
|
0 |
Ha később Ucinet-et szeretnénk használni az elemzéskor, célszerű rögtön ebbe írni az adatokat, mert az adatok ugyan másolhatók, de a keretek nem. Ha más adatbázis-kezelőben dolgozunk, akkor is hasonló mátrixot kell készítenünk. A keretfájl elkészítéséhez először nyissuk meg a Ucinet programot.
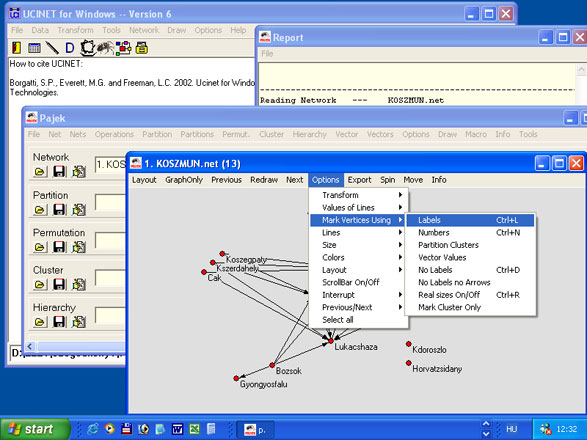
7. 1. ábra: a Ucinet programcsomag menüsora és ikonsora.
Kattintsunk az ikonok közül a táblázatra. A megjelenő új ablak a Ucinet adatbázis kezelő. A táblázat szélére kattintva a nevet, a közepébe az értéket írhatjuk. A szoftver nem ismeri a magyar hosszú ő és ű betűket, az egységes írásmód végett a nevek lehetőleg csak az angol ABC karaktereit tartalmazzák. Kezdésképpen, amíg nincsenek adataink, a főátlót írjuk tele 0-val. A főátlót képező 0-kat azért érdemes beírni az elején a keretfájlba, mert később, adatbevitelkor (különösen nagyobb táblázatoknál) segít megtalálni, hogy hol is tartunk. Példaként egy régebbi munkánk, a kőszegi kistérség településközi kapcsolatainak adatait használom fel[1].
A Ucinet adatbázis-kezelő képe
Ha eddig nem tettük, itt az ideje, hogy elgondolkodjunk, milyen típusú kapcsolatokat definiálunk a szereplők között. Térségek vizsgálatakor például kérdés lehet, hogy honnan hová járnak dolgozni az emberek, hová költöznek lakni, vagy mely települések tartanak fenn valamilyen közös intézményt, stb. Mindezekre az esetekre majd egy-egy újabb mátrixot kell kitölteni. Egy településkutatás során – a mindenkori kutatási kérdésektől függően – 8-10, vagy több adatmátrixot is létrehozhatunk. Célszerű olyan beszédes fájlnevet adni, amiből könnyen ráismerünk a kapcsolat jellegére. A „varos4.##h” név helyett például javasolt „napiingazas.##h” nevet adni. Ez a tanács szájbarágósnak tűnhet, ezért leszögezem: tisztában vagyok azzal, hogy Ön, kedves olvasó, látott már számítógépet és adott már fájlneveket. A Ucinet programnál az adatmátrix elnevezésének azért van különös jelentősége, mert elemzés során az adatbázist nem nyitjuk meg, viszont minden egyes parancs során meg kell adni a hivatkozást arra a fájlra, amin az elemzést el kívánjuk végeztetni. Más adatbázis-kezelőknél ez nincs feltétlenül így: ott általában megnyitunk egy fájlt, a nekünk tetsző szempontok szerint elemezzük, majd a végén bezárjuk, és semmiképp sem kell minden egyes parancshoz kikeresni az adatbázist.
Egy-egy adatmátrix kitöltéséhez először azt kell eldöntenünk, hogy szimmetrikus vagy aszimmetrikus módot használjunk. Az aszimmetrikus módnál van értelme a kapcsolat irányának, a szimmetrikusnál nem beszélhetünk irányokról. Például rokonság esetében a szülő-gyerek kapcsolat aszimmetrikus, míg a „házastárs” vagy „unokatestvér” szimmetrikus. Cégvilágban a partneri kapcsolat szimmetrikus, a beszállítói aszimmetrikus, míg települések között az úthálózat mindig szimmetrikus, a forgalom azonban lehet aszimmetrikus kapcsolat.
A kapcsolatok beírásakor a szabály: „sor, oszlop”, azaz a sorból mutat a kapcsolat az oszlop felé. Az alábbi egyszerű gráf például a következőképp néz ki mátrix formában:
7.2-es ábra: kapcsolatok jelölése adatmátrixban és gráf formában
|
|
1 |
2 |
3 |
4 |
1 2 |
|
1 |
0 |
1 |
|
1 |
|
|
2 |
|
0 |
|
|
|
|
3 |
|
|
0 |
1 |
3 4 |
|
4 |
|
|
1 |
0 |
|
![]()
![]()
![]()
Az adatbevitel során először mentsük el a keretfájlt új néven, majd válasszuk ki a szimmetrikus/aszimmetrikus (normal) üzemmódot a Ucinet adatbázis-kezelőjében, a képernyő bal oldalán. Ez szimmetrikus módban némiképp megkönnyíti az adatbevitelt: a sor-oszlop kombinációt beírva megjelenik az oszlop-sor változat is. Újabb programverziók az üres helyeket automatikusan 0-ként kezelik, ezért csak az 1 értékeket kell beírni, oda, ahol van kapcsolat.
A Ucinet egy-egy mátrixból két fájlt készít, .##h és .##d kiterjesztéssel. Megnyitáskor csak a .##h fájlok láthatók. A fájlok csak néhány kapcsolatháló elemző programmal kompatibilisek, kölcsönösségi alapon. A program nem tud más kiterjesztésű, így például .xls vagy .sav fájlokat megnyitni. Ennek ellenére az adatokat bármely más adatbázis-kezelő szoftverbe is begépelhetjük. Ha összeállt az adatbázisunk, akkor egyszerűen másolás-beillesztés paranccsal áttehető a Ucinet keretfájlba.
A begépelt adatbázist érdemes vizuálisan is megjeleníteni, azaz felvázolni egy gráfot. Az egyszerű hálókat mind a kutatónak, mind pedig a későbbi olvasóknak könnyebb grafikusan, gráf formában áttekinteni, mint mátrix alakban. E helyütt a gráfok rajzolásának gyakorlati teendőit vesszük számba.
A kapcsolatháló grafikai képének felvázolása sokszor a kutató számára is adhat ötleteket, érdemes az elemzést ezzel kezdeni. Először is zárjuk be az elkészített adatmátrixokat, majd a Ucinet menü ikonjai közül válasszuk ki az utolsó előtti ikont (NetDraw; lásd 1. ábra.). Erre kattintva egy újabb ablak jelenik meg. Itt válasszuk a File – Open – Ucinet Dataset – Network menüt, (vagy kattintsunk egyet a nyitott fájl ikonra), ekkor egy újabb kisablak jelenik meg. Válasszuk ki az egyik adatbázisunkat, és nyomjunk egy Open-t. A Netdraw válaszul megrajzolja a kapcsolatháló képét.
7. 3. ábra. Rajzolás NetDraw-val. Példa: honnan hová jártak dolgozni az emberek a kőszegi kistérségben, 1998-ban.
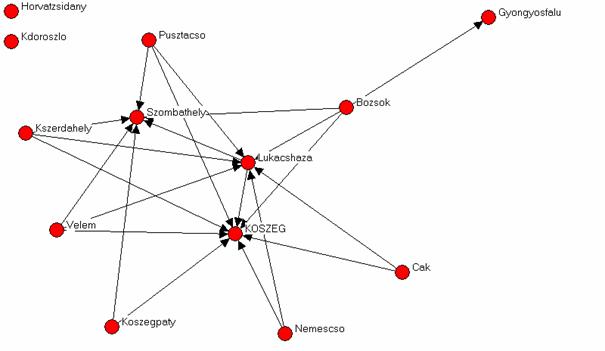
Az ábrára rátekintve látható, hogy a kistérség munkahely szempontból erősen centralizált. A központi szereplők Kőszeg, kisebb mértékben Lukácsháza, illetve Szombathely. Szombathely természetesen nem a kistérség része, azért szerepel az adatbázisban, mert jelentős elszívó hatást gyakorol a helyi munkaerőpiacra[2]. Az ábráról az is leolvasható, hogy mely településekről járnak az emberek Kőszegre dolgozni, melyekről Kőszegre és Lukácsházára egyaránt, stb.
A képről azért olvasható le ez a sok információ, mert a NetDraw olyan szoftver, amely rajzolás közben elemez is: ismétlődő műveletek (iterációk) sorát hajtja végre, hogy végül az egymáshoz hasonló helyzetű szereplők kerüljenek egymás mellé. Alapértelmezésben a központi szereplők kerülnek középre, körülöttük helyezkednek el a hozzájuk kapcsolódó szereplők, az ugyanahhoz a taghoz kapcsolódó szereplők egymás mellé, az elszigeteltek pedig a bal felső sarokba kerülnek. Ha játszunk az ikonsoron, akkor átrendezhetjük a grafikai képet más elvek szerint, például úgy, hogy körben legyenek a szereplők, vagy sokdimenziós skálázás szerint csoportokba osztva. Kézzel is belekontárkodhatunk a rajzba, például egérrel megfogva a pontokat arrébb húzhatjuk, ilyenkor természetesen a kapcsolati szálak is megnyúlnak. Ha a kép olyan, amilyet szeretnénk, elmenthetjük kép fájlként (Save diagram as).
A grafikai kép alapján kialakuló sejtésünket természetesen matematikai-statisztikai elemző módszerekkel is igazolnunk kell. A példában szereplő kis elemszám esetén „ránézéses módszerrel” is kialakulhatnak sejtéseink, de nagyobb elemszám, több száz vagy több ezer kapcsolat esetén a grafikai kép átláthatatlan, ezért még a sejtéseket is mátrix alapú elemzésekre kell alapozni.
Míg a NetDraw kifejezetten grafikai programcsomag, korlátozott elemző lehetőségekkel, a Szlovéniában fejlesztett Pajek alapvetően egy matematikai-statisztikai szoftver, amely elsősorban, (de nem kizárólag) kapcsolatháló elemzést tud végezni, és ráadásul hasonló grafikai lehetőségeket biztosít, mint a Net-Draw. A Ucinet ikonsorából a „mérges pókra” kattintva egy új ablak bukkan fel, Export to Pajek címmel. A legfelső sor (import dataset) melletti három pontra kattintva megkereshetjük és kiválaszthatjuk a kívánt adatbázist. Ezt jóváhagyjuk (OK), majd a engedélyezzük a Pajek betöltését. Ekkor két újabb ablak jelenik meg, melyek közül a Pajek feliratút kell választanunk. Ennek felső sorában látható, hogy a program behívta a keresett adatbázist. Pajekben elemezhetnénk is az adatokat, de a Pajek elemzési lehetőségeivel jelen kötet nem foglalkozik. Grafikai ábrázolásra a menüsor Draw – Draw menüjét kell választani. Erre kattintva egy újabb ablak jelenik meg, felül menüsor, alatta szürke alapon hasonló ábra, mint korábban. A Pajek alapvetően nagy hálók elemzésére és rajzolására alkalmas szoftver, ezért a grafika alapbeállításként kis pontocskákat rajzol, és nem tüntet fel címkéket. Ha ezen változtatni szeretnénk, az Options menüben válogathatunk a különböző beállítási lehetőségek között: címkék, irányok, méretek beállítása, stb.. A kész képet végül Export menüpont alól menthetjük el grafikai formátumban.
7. 3. ábra. Rajzolás Pajek-kel. Példa: honnan hová jártak dolgozni az emberek a kőszegi kistérségben, 1998-ban.
A Mage programcsomagot eredetileg mikrobiológiai kutatások segítésére hozták létre. A biokémia szerves vegyületei hosszú és összetett láncokat alkotnak, amelyeket a kutatóknak nehéz volt elképzelniük. A molekula makettje nagy segítség a kutatóknak, hiszen meg lehet nézni, elforgatni, értelmezni az egyes atomok helyét. A Mage alapvetően térbeli láncolatok makettjét készíti el, és egy kis képernyőn bemutatja egy vetületét. A Mage ábra háromdimenziós hatású és forgatható, az egyes vetületek kép fájlként menthetők. A könnyebb érthetőség kedvéért az egyes szereplők címkézhetők.
A Mage A Ucinet ikonsorából a kör alakú hálóra kattintva hívható be, a Pajek-hez hasonló módon. A megjelenő program közepén fekete alapon látható az ábra, jobb szélén a menüsor. A menüvel ki-be kapcsolhatjuk a címkék, a pontok vagy az élek feltüntetését, állíthatjuk a kép kontrasztosságát, ráközelíthetünk egy részletre. A fekete alaphoz nyúlva elforgathatjuk a képet, és más nézőpontból csodálkozhatunk rá. A gráf formáján változtatni nem tudunk, azaz a pontok nem helyezhetők át. Ez főleg akkor gond, ha egy nagy sűrűségű hálóban van néhány izolált szereplő. A Mage grafikai algoritmusa a távoli szereplőket külön csoportnak tekinti, és a teret egyenlően osztja el a csoportok között. Ennek eredményeképp a sűrű hálót egy kis csomóba zsúfolja a képernyő közepén, amelyre erősen ráközelítve sem tudunk kivenni semmit. A Mage ezért főleg akkor használható, ha nem túl nagy elemszámú, viszonylag kis sűrűségű hálót akarunk ábrázolni, amelyben az elszigetelt, azaz kapcsolat nélküli szereplőket nem tüntetjük fel. A Mage programot nem csak azért érdemes használni, mert több oldalról enged rácsodálkozni a hálóra, hanem azért is, mert a szép 3D grafikák jól mutatnak a készítendő tanulmányban.
7.5. ábra: Mage program. Példa: honnan hová költöznek az emberek a kőszegi kistérségben.

A vizualizáció szerepe elsősorban az, hogy kutatási eredményt egyszerű, érthető formában közzétegyük. A 7.2. ábra egy négy elemű háló tagjait mutatta be gráf és mátrix formában. Meggyőződhetünk róla, hogy a gráf első ránézésre sokkal többet mond, mint egy mátrix. A gráfoknak ez a sajátsága különösen alkalmazott kutatásnál előny. Egy fejlesztési terv esetében a megrendelő és a műszaki kollegák várhatóan nem fognak elmélyülni adatmátrixok értelmezésében, könnyen átlátható, világos közléseket várnak.
A gráf akkor hasznos, ha pontosan azt tükrözi, amit mondani akarunk. Először tehát el kell döntenünk, milyen üzenetet akarunk sugallni az elemzések alapján. Az elemzési szakasz után érdemes új, beszédes ábrákat készíteni, amelyek kihasználják a bemutatott szoftverek kisegítő grafikai lehetőségeit, változtatnak a gráf alakján, színein és feliratozásán.
Kis hálózati csoportok esetében a kapcsolati ábra megtekintésekor már többnyire vannak sejtéseink a háló struktúrájáról. Ilyenkor a különböző számításoknak az a szerepe, hogy megerősítsen vagy épp’ ellenkezőleg, elbizonytalanítson bennünket. Nagy elemszám (nagy méretű háló) esetén viszont a sejtéseink is csak az elemző eljárások során alakulhatnak ki. A következőkben egy kis elemszámú példán mutatjuk be a sűrűség néhány mérőszámát, az előző oldalakról már ismert, a kőszegi kistérségben a munkaerő napi ingázását mutató adatmátrix alapján. Kulcsfogalmak:
Sűrűség (density)
Kapcsolatháló sűrűsége
Ego háló sűrűség
A háló sűrűsége a lehetséges és a létező kapcsolatok arányát jelenti. Egy n elemű hálóban a lehetséges kapcsolatok száma n*(n-1). Ha minden lehetséges kapcsolat valóban létezik, azaz mindenki kapcsolatban áll mindenkivel, akkor a sűrűség értéke 1. A „0” sűrűség érték azt jelenti, hogy senki sem áll kapcsolatban senkivel. A sűrűség értéke mindig 0 és 1 közötti szám, melynek magasabb értékei nagyobb hálózati sűrűséget jeleznek.
A teljes háló sűrűségéhez hasonló módon számolhatjuk ki az egyes pontok sűrűségét, ami az egyes pontok tényleges kapcsolata az összes lehetséges kapcsolatukhoz képest. A mátrix, mint korábban írtuk, lehet szimmetrikus vagy aszimmetrikus, attól függően, hogy a kapcsolatok irányítottak vagy sem. Aszimmetrikus mátrix esetén el kell döntenünk, hogy oszlopok vagy sorok, azaz a beérkező vagy a kifutó kapcsolatok alapján szeretnénk-e a pontok sűrűségét mérni. Az egyes szereplők kapcsolatainak számát egyébként a szakma nyelvén foknak, a beérkező és kifelé mutató kapcsolatok számát pedig kifoknak és befoknak mondjuk.
A Ucinet programcsomag menüjében a Tools – Statistics – Unvariate paranccsal választhatjuk ki a sűrűség számítását. A megjelenő ablak második sorában választhatjuk ki, hogy a teljes mátrix sűrűségét kérjük-e le, vagy az egyes elemekét, sorok vagy oszlopok szerint. A következő Ucinet jelentés a teljes mátrixra vonatkozó legfontosabb adatokat tartalmazza. Az adatbázis a kőszegi kistérség lakosainak napi ingázására vonatkozik, azaz azt mutatja, hogy mely településről hova járnak az emberek dolgozni.
UNIVARIATE STATISTICS
--------------------------------------------------------------------------------
Dimension: MATRIX
Diagonal valid? NO
Input dataset: D:\...\KOSZMUN
Descriptive Statistics
1
-------
1 Mean 0.135
2 Std Dev 0.341
3 Sum 21.000
4 Variance 0.116
5 SSQ 21.000
6 MCSSQ 18.173
7 Euc Norm 4.583
8 Minimum 0.000
9 Maximum 1.000
10 N of Obs 156.000
Statistics saved as dataset D:\...\UnivariateStats
----------------------------------------
Running time: 00:00:01
Output generated: 28 mar 04 21:11:25
Copyright (c) 1999-2004 Analytic Technologies
A táblázat feletti három sor közül az egyik (Diagonal valid? No) azt jelzi, hogy a főátlót, azaz a magával való kapcsolatot, jelen esetben a saját településén dolgozó munkavállalót nem értelmezzük.
A jelentés táblázatának első értéke (átlag, mean) a sűrűség. Értéke, 0,135 azt mutatja, hogy a lehetséges kapcsolatok 13,5%-a létezik a valóságban. A kőszegi kistérségi napi ingázásra vonatkozóan ez azt jelenti, hogy a legtöbb településről nem járnak át a többi településre, a lehetséges ingázási utak 87%-a valóságban nem létezik.
Az adatok (standard) szórása (Std. Dev.) azt jelzi, mekkora különbségek mutatkoznak e téren az egyes települések között. Ha a kapcsolatok egyenlően oszlanának meg, azaz példánkban minden településre ugyanannyi helyről jönnének dolgozni az emberek és viszont, akkor a szórás 0 lenne. A szórás értéke az átlaghoz képest értelmezhető. Jelen esetben a szórás 0,341, azaz az átlag két-háromszorosa, ez extrém nagynak számít, azaz a kapcsolatok rendkívül egyenlőtlenül oszlanak meg. Ez példánkban azt jelenti, hogy a kistérség települései egyenlőtlenül szerepelnek a munkaerőpiacon.
A „sum” a kapcsolatok összes számát mutatja, jelen esetben 21 kapcsolat van a települések között. Ez alapján a sűrűség értékét számológéppel is könnyen kiszámolhatnánk: Sűrűség érték = létező/lehetséges / kapcsolatok, azaz a 13 település esetében 21 / 13*12 = 0,1346.
Az oszlop utolsó értéke, az esetszám (N. of observations), kapcsolatháló elemzésről lévén szó nem a szereplőkre, hanem a kapcsolatokra vonatkozik. 13 település esetén a diád kapcsolatok száma n*n-1, azaz 13*12, jelen esetben 156.
A többi információtól általában eltekinthetünk. A variancia a szórás négyzete, a négyzetes összeg (Ssq: sum of squares) dichotóm változó esetén ugyanaz, mint a „sum”, a minimum és maximum érték pedig értelemszerűen 0 és 1, hiszen csak ez a két érték szerepel az adatmátrixunkban.
Ha nem csak 0 és 1 értékek vannak az adatbázisban, akkor a sűrűséget számító algoritmus nem működik helyesen, azaz nem a lehetséges és a valós kapcsolatok arányát fogja mutatni, hanem egy értelmezhetetlen eredményt. Érdemes kipróbálni, mennyire más eredmények jönnek ki, ha egy egyszerű adatbázisban az egyesek helyére más értékeket írunk. Ez egyébként a jelen fejezetben ismertetett valamennyi eljárásra igaz, mindegyik csak dichotóm változókkal működik helyesen.
A bemutatott példa egy kistérség 13 településére vonatkozott. Most képzeljük el, hogy egy óriási sokaság esetében hasonló eredményt kapunk. Nyilvánvaló, hogy a kapott információ nem mondana sokat, de sugalmazhat például egy olyan kérdést, hogy ha valóban egyenlőtlenül oszlanak el a kapcsolatok a szereplők között, akkor vajon melyek a kapcsolati központok. Kérdés lehet még, hogy a többi szereplő egyformán periférikus helyzetű-e, vagy köztük is mutatkoznak különbségek. Lefordítva a kistérségi problémára: egy munkaerő-piaci központ van a térségben, vagy több, és van-e különbség napi ingázás tekintetében az egyes települések között. A kérdés megválaszolásában segít az ego háló sűrűség vizsgálat.
Ego háló sűrűség mérésnél döntés kérdése, hogy sorok vagy oszlopok, azaz kifok vagy befok alapján vizsgálódunk. Ha – példánkban – arra vagyunk kíváncsiak, hogy mely település a munkaerő-piaci központ, hová járnak az emberek dolgozni, akkor oszlopok szerinti statisztikát kell kérni.
Dimension: COLUMNS
Diagonal valid? NO
Input dataset: D:\...\KOSZMUN
Descriptive Statistics
1 2 3 4 5 6 7 8 9 10 11 12 13
Koszeg Puszta Nemesc Gyongy Lukacs Horvat Velem Cak Bozsok Kszerd Kdoros KOSZEG Szomba
------ ------ ------ ------ ------ ------ ------ ------ ------ ------ ------ ------ ------
1 Mean 0.000 0.000 0.000 0.083 0.500 0.000 0.000 0.000 0.000 0.000 0.000 0.667 0.500
2 Std Dev 0.000 0.000 0.000 0.276 0.500 0.000 0.000 0.000 0.000 0.000 0.000 0.471 0.500
3 Sum 0.000 0.000 0.000 1.000 6.000 0.000 0.000 0.000 0.000 0.000 0.000 8.000 6.000
4 Variance 0.000 0.000 0.000 0.076 0.250 0.000 0.000 0.000 0.000 0.000 0.000 0.222 0.250
5 SSQ 0.000 0.000 0.000 1.000 6.000 0.000 0.000 0.000 0.000 0.000 0.000 8.000 6.000
6 MCSSQ 0.000 0.000 0.000 0.917 3.000 0.000 0.000 0.000 0.000 0.000 0.000 2.667 3.000
7 Euc Norm 0.000 0.000 0.000 1.000 2.449 0.000 0.000 0.000 0.000 0.000 0.000 2.828 2.449
8 Minimum 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
9 Maximum 0.000 0.000 0.000 1.000 1.000 0.000 0.000 0.000 0.000 0.000 0.000 1.000 1.000
10 N of Obs 12.000 12.000 12.000 12.000 12.000 12.000 12.000 12.000 12.000 12.000 12.000 12.000 12.000
Az adattáblából látszik, hogy Kőszeg befok szerinti sűrűsége 66,7%-os, azaz a kistérség településeinek kétharmadáról járnak be emberek Kőszegre dolgozni. A települések feléről járnak Szombathelyre, és szintén feléről Lukácsházára. A többi településre gyakorlatilag nem járnak sehonnan, a napi ingázás a központok felé egyirányú.
Az ego háló sűrűséghez hasonló elven működnek a központiság (centralitás) mérőszámai is. A sűrűség a lehetséges és a valós kapcsolatok arányát méri, a központiság pedig azt, hogy a valóban létező kapcsolatok közül mennyit birtokol az adott szereplő. Könnyen belátható, hogy központiságot alapvetően ego háló elemzésére találták ki: teljes háló esetén a valós kapcsolatok arányát saját magához kellene hasonlítani, azaz az értéke egy lenne. A központiság elsősorban ego háló sajátságot mér, bár teljes hálóra vonatkozó információkat is tartalmaz. Kulcskifejezések:
Központiság (centrality)
Fok
Freeman fokszám
Közelség
Közöttiség
Sajátvektor
Bonachich hatalmi mutató (Bonachich power)
A központiság legkézenfekvőbb mérőszáma az egyes pontok kapcsolatainak (fokainak) számát viszonyítja az összes kapcsolathoz. Ezt fokszám-központiságnak (degree centrality) nevezzük. A mérőszámot a szociológus Linton Freeman (1979[1]) finomította tovább, a gyakorlatban általában Freeman fokszám központiságot (Freeman’ s degree centrality) használunk.
Irányított kapcsolatok esetén a fokszám alapján olyan kijelentést is tehetünk, hogy mely szereplőnek nagy a presztízse (amelyiknek nagyobb a befoka, mint a kifoka), vagy a befolyása (nagyobb kifok, mint befok).
A fokszám központiságon kívül több különböző mérőszám áll rendelkezésre. A Ucinet-tel is végezhető műveletek közül az (angol nevükön) reach centrality, flow betweenness, power, information és influence centrality mérőszámokkal jelen fejezetben terjedelmi okokból nem foglalkozunk, de a kötet szöveggyűjteményében Kürtösi Zsófia írása röviden beszámol róluk. Ugyanott található a továbbiakban értelmezésre kerülő eljárások részletesebb bemutatása is matematikai formulákkal, etc.
A következő eredményt a szokásos adatmátrixból nyertük a kőszegi kistérség ingázóiról. A Ucinet menüsorából a Network – Centrality – Multiple measures parancsot adtuk ki. Ekkor négy különböző algoritmus: Freeman fokszám (degree), közelség (closeness), közöttiség (betweenness) és sajátvektor (eigenvector) alapján számol a program központiságot.
MULTIPLE CENTRALITY MEASURES
--------------------------------------------------------------------------------
Input dataset: D:\...\KOSZMUN
Output centrality measures: D:\...\Centrality
Normalized Centrality Measures
1 2 3 4
Degree Closeness Betweenness Eigenvector
------------ ------------ ------------ ------------
1 Koszegpaty 16.667 26.667 0.253 24.394
2 Pusztacso 25.000 27.273 0.253 38.828
3 Nemescso 16.667 26.667 0.000 27.851
4 Gyongyosfalu 8.333 23.529 0.000 8.501
5 Lukacshaza 66.667 31.579 16.162 68.943
6 Horvatzsidany 0.000 7.692 0.000 0.000
7 Velem 25.000 27.273 0.253 38.828
8 Cak 16.667 26.667 0.000 27.851
9 Bozsok 33.333 28.571 13.889 40.607
10 Kszerdahely 25.000 27.273 0.253 38.828
11 Kdoroszlo 0.000 7.692 0.000 0.000
12 KOSZEG 66.667 31.579 20.455 64.090
13 Szombathely 50.000 30.000 9.091 52.429
Az eljárás során az algoritmus a kapcsolatok irányát nem vonja be az elemzésbe, azaz a mátrixot szimmetrikussá teszi. Emiatt az eljárás – mint látni fogjuk – gyakorlatilag alkalmatlan a konkrét példa elemzésére, azaz a kistérségi munkaerő-piaci kapcsolatok vizsgálatára.
Ti, akik ezt olvassátok, a túlnyomórészt önállóan képezik tovább magukat. Az autodidakta tanulás során az ember jobbára a hibáiból tanul, ha feltűnik neki, hogy az elemzés értékei ellentmondanak a józan ész szerint várható eredményeknek. Jelen „rossz” példa remélhetően életszagúbb, és ezért többet lehet tanulni belőle, mint egy adekvát elemzésből. A „rossz elemzések” után egy „jó” elemzést is bemutatunk, de azt már csak egyetlen mérési eljárással.
A Freeman fokszámon alapuló központiság eljárásnál a legnagyobb megfigyelt fok mínusz az összes többi fok különbségeinek összegét osztjuk az elméletileg lehetséges legnagyobb különbséggel. Az együttható normalizált, értéke akkor egy, ha egy központi szereplő tart össze egy hálót, és nulla, ha minden szereplőnek épp ugyanannyi kapcsolata van. (Gyakorlatlan kutatóknak általában könnyebb a nem normalizált adatokból kiindulni, azaz számszerűen vizsgálni a ki- és befokokat.) Az eredmények alapján Kőszeg és Lukácsháza kiterjedtebb helyi munkaerőpiaci hálóval rendelkezik, mint Szombathely. Egyes falvak 0,25 – 0,33, mások 0,16 értékkel rendelkeznek. A eredmények alapján Kőszeg központisága nem tűnik olyan kiugróan nagynak, mint a sűrűség eredmények alapján. Az eredmények egy kiegyensúlyozott munkaerő-piacról árulkodnak, ahol sokan sokfelé járnak munkába. Fogjunk gyanút! Ezek a furcsa eredmények a kapcsolatok szimmetrikussá alakítása miatt jönnek ki. A valóságban Lukácsházára épp ennyi településről járnak dolgozni, mint Szombathelyre, csak éppen Lukácsházáról is járnak el dolgozni, amit a szimmetrikus elemzés egybemos. Az elemzési algoritmus csökkenti Kőszeg vezető szerepét is: ugyan a kistérségben valamennyi szinte településsel van kapcsolata, de a többi településnek is van jellemzően 2-3 kapcsolata, így az előny nem kiugró. Attól lenne kiugró, ha a kapcsolatok irányát is figyelembe vennénk, és kiderülne, hogy Kőszeg valamennyi kapcsolata felé mutat (befok), a többi településé pedig kifok.
A fokszám központiság első kritikája azt fogalmazta meg, hogy a mérőszám csak a közvetlen kapcsolatokat méri, figyelmen kívül hagyva a „kapcsolat kapcsolatait”. Két pont geodézikus távolsága azt jelenti, hogy a két pont hány szereplőn keresztül érintkezhet egymással. Két pont akkor közeli egy kapcsolathálóban, ha egy (vagy minél kevesebb) lépésből elérik egymást. A közelség központiság azt nézi, hogy a kiválasztott pont hány lépésből éri el a háló valamennyi pontját, és ezt az összes pont hasonló paraméteréhez (azaz a geodézikus távolságok összegéhez) viszonyítja. Akkor magas egy ego közelségi központisága, ha a legtöbb szereplőt közvetlenül vagy kevés lépéssel el tudja érni, más szereplők pedig nem. Visszalapozva a 7.3 ábrához, vagy felidézve az ego sűrűség mutatót, láthatjuk, hogy Kőszeg és Szombathely kiugróan magas központiságú kell, hogy legyen. Jelen elemzés eredményei szerint azonban minden település közelség-központisága 30 % körül mozog. Ha ilyent látunk, kezdjünk el gyanakodni! A magyarázat, hogy az algoritmus nem működik, ha a hálóban elszigetelt szereplők is vannak. Látható például, hogy a mi esetünkben például Horvátzsidány (ahonnan senki nem jár el dolgozni, és oda sem járnak máshonnan) szintén komoly közelség-értéket kapott. Ez jól mutatja, hogy ez az eredmény érvénytelen. Az eljárást meg kellene ismételni úgy, hogy az elszigetelt szereplők sorait és oszlopait kitöröljük az adatmátrixból.
A közöttiség (betweenness) központiság egészen eltérő megfontoláson alapul: feltételezi, hogy egy szereplő azért sikeres egy hálóban, mert közvetítő szerepben van két csoport között. A közvetítő szerep nem feltétlenül jelent központi szerepet, bár ez is elképzelhető. Jelen esetben a különböző ingázó településcsoportok között Kőszegen és Lukácsházán kívül Bozsok tűnik közvetítő szerepűnek. Jelen példa értelmezésekor ne felejtsük el, hogy a kapcsolatokat szimmetrikusnak tételeztük, holott a valóságban irányított kapcsolatokról van szó! Ha egybevetjük az eredményt a 7.3. ábrával, rögtön láthatjuk, hogy az értelmezés nem jó, Bozsok nettó munkaerő-kínáló település. Ezt az eredményt az aszimmetrikus módon megismételt elemzés ki fogja mutatni. Ha egyébként szimmetrikus kapcsolatokról lenne szó (például egy úthálózati térképet néznénk), akkor az eredmény a valóságot tükrözné, hiszen Bozsok lenne az egyedüli közvetítő, (tekintsünk az ábrára) Gyöngyösfalu és a külvilág között.
A sajátvektor (eigenvector) alapján számított központiságot kitalálója, a szociológus Phillip Bonachich[2] (1987) után Bonachich centralitásnak vagy Bonachich hatalmi mutatónak (Bonachich power) nevezzük. Mint erre a sajátvektor elnevezés is utal, az algoritmus alapja a faktorelemzés. Az eljárás a közelséghez hasonló megfontoláson alapszik, de inkább tekintettel van az egész hálóra, és kevéssé a helyi környezetre. Ezek az előnyök persze csak nagy hálók esetében érvényesülnek, kis hálóknál a sajátvektor és a közelség központiság értékek között minimális a különbség. Jelen esetben viszont látható, hogy a Bonachich hatalmi mutatónak közelebb áll a józan eszünkkel várható eredményhez, mint a közelség-központiság. Ez azért van, mert az algoritmus nem érzékeny az elszigetelt értékekre. Az eredmények azért így is „gyanúsak”, az eljárást aszimmetrikus módban lenne jó megismételni. A Ucinet 6. verziója azonban csak szimmetrikus adatmátrixon tud Bonachich központiságot számolni. Ennek köszönhető egyébként az is, hogy ha a „Multiple measures” parancsot adjuk ki, a program mind a négy elemzést szimmetrikus alapokon végzi. Éppen ezért ne ezt a parancsot adjuk ki, hanem döntsük el, hogy melyik központiságot akarjuk használni, és az adatmátrixunknak megfelelően a szimmetrikus vagy aszimmetrikus módot futtassuk. A Bonachich erőt csak akkor érdemes számolni, ha szimmetrikus és kifejezetten nagy méretű adatmátrixunk van.
Anélkül, hogy az adekvát elemzéseket mind bemutatnánk, bemutatunk egy Freeman központiság elemzést. A parancsot a menüből Network – centrality – degree útvonalon érjük el. A megjelenő kis ablak második sorát (Treat data as symmetric) állítsuk át aszimmetrikusra (No), majd ha kiválasztottuk a megfelelő adatmátrixot, nyomjunk OK-t.
FREEMAN'S DEGREE CENTRALITY MEASURES
--------------------------------------------------------------------------------
Diagonal valid? NO
Model: ASYMMETRIC
Input dataset: D:\...\KOSZMUN
1 2 3 4
OutDegree InDegree NrmOutDeg NrmInDeg
------------ ------------ ------------ ------------
9 Bozsok 4.000 0.000 33.333 0.000
7 Velem 3.000 0.000 25.000 0.000
2 Pusztacso 3.000 0.000 25.000 0.000
10 Kszerdahely 3.000 0.000 25.000 0.000
5 Lukacshaza 2.000 6.000 16.667 50.000
3 Nemescso 2.000 0.000 16.667 0.000
1 Koszegpaty 2.000 0.000 16.667 0.000
8 Cak 2.000 0.000 16.667 0.000
6 Horvatzsidany 0.000 0.000 0.000 0.000
4 Gyongyosfalu 0.000 1.000 0.000 8.333
11 Kdoroszlo 0.000 0.000 0.000 0.000
12 KOSZEG 0.000 8.000 0.000 66.667
13 Szombathely 0.000 6.000 0.000 50.000
Az eredmények első oszlopa a kifokokat tartalmazza csökkenő sorrendben, a harmadik pedig a Freeman együttható alapján számított, normalizált, azaz 0 és 1 közötti együtthatót. A második oszlop a befokokat, a negyedik pedig a befokok alapján számított normalizált értéket mutatja. Ezek az értékek elfogadhatók. Látható például, hogy Kőszeg és Bozsok magas értéke nem hasonlóságot, hanem a lehető legnagyobb különbséget takarja: Kőszeg a legmagasabb, Bozsok pedig a legalacsonyabb presztízsű szereplő (természetesen csak kapcsolathálózati értelemben). Ugyancsak nem kerül Szombathely elébe Lukácsháza, mert a ki- és befokok nem adódnak össze.
Az elemzés – egyébként a többi elemzés is, de ezeket nem mutatjuk be – nem csak az egyes szereplőkre, hanem az egész hálóra vonatkozóan is tartalmaz megállapításokat.
DESCRIPTIVE STATISTICS
1 2 3 4
OutDegree InDegree NrmOutDeg NrmInDeg
------------ ------------ ------------ ------------
1 Mean 1.615 1.615 13.462 13.462
2 Std Dev 1.389 2.816 11.574 23.465
3 Sum 21.000 21.000 175.000 175.000
4 Variance 1.929 7.929 133.958 550.625
5 SSQ 59.000 137.000 4097.222 9513.889
6 MCSSQ 25.077 103.077 1741.453 7158.120
7 Euc Norm 7.681 11.705 64.010 97.539
8 Minimum 0.000 0.000 0.000 0.000
9 Maximum 4.000 8.000 33.333 66.667
Network Centralization (Outdegree) = 21.528%
Network Centralization (Indegree) = 57.639%
NOTE: For valued data, both the normalized centrality and the centralization index may be larger than 100%.
----------------------------------------
Running time: 00:00:01
Output generated: 29 mar 04 02:47:51
Copyright (c) 1999-2004 Analytic Technologies
A két legfontosabb információ az alsó két sor, azaz a ki- és befok alapján számított háló központiság. Kifok alapján a háló központisága normális (21,5%), azaz sok szereplőtől indulnak kifelé kapcsolatok, és ilyen téren nem nagy a különbség köztük. Befok alapján viszont 57,6%, nagyon magas centralizáltságról beszélhetünk, azaz a kiinduló kapcsolatokat néhány központ szipkázza be. Érdekes (ezzel egybevágó) eredményt mutat a táblázat második sora, a szórás: míg a kifok esetében a szórás mértéke az átlagos kifok alatt marad, addig befok esetén a szórás kétszer akkora, mint az átlagos fokszám maga. Ha nem lennének más ismereteink a sokaságról, akkor pusztán ez alapján az információ alapján is megállapíthatnánk, hogy a sok helyről kiinduló kapcsolatokat néhány központ egyenlőtlen módon gyűjti be – ahogy ez igaz is a vizsgált kistérségi munkaerőpiacra.
7. CONCOR strukturális ekvivalencia elemzés
A kapcsolatháló elemzés kelléktára és a(z) Ucinet programcsomag számos elemző eljárást tartalmaz. Valamennyinek a bemutatására jelen kötetben nincs lehetőség. Önkényes módon két elemzési eljárást választottam ki bemutatásra, a CONCOR és a QAP elemzéseket. A jelen fejezetben be nem mutatott elemző technikák egy részéről (például: klikkek, n-klikkek, automorf és reguláris ekvivalencia, háló dinamikai sajátságok, stb.) olvashatnak Szántó Zoltán és Kürtösi Zsófia írásaiban, www.socialnetwork.hu , illetve a következő hetekben, Vedres Balázs e-leckéiben. Kulcsfogalmak:
Strukturális ekvivalencia
Blokk elemzés
CONCOR elemzés
Nagy mennyiségű adat esetében sokszor érdemes arra törekedni, hogy az adatokat néhány csoportba soroljuk, és a továbbiakban a kevés számú csoport kapcsolatait tárgyaljuk. A CONCOR elemzés – más ekvivalencia eljárásokhoz hasonlóan – épp erre alkalmas. A csoportosítás alapja a strukturális ekvivalencia.
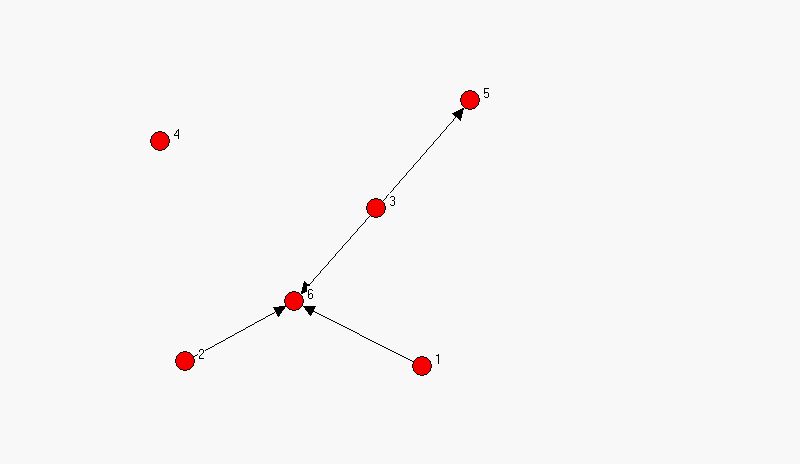
Tekintsünk a következő egyszerű gráfra!
7.6. ábra: Strukturális ekvivalencia ás a blokkok.
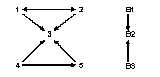
Tegyük fel, hogy a számok településeket jelentenek, a nyilak pedig azt jelzik, hogy honnan hová járnak az emberek dolgozni. Látható, hogy a „3” település valami központféle lehet, mert mindenki oda jár. Az „1” és „2” településről nem csak „3”-ba, hanem egymás felé is ingáznak emberek. Mondhatjuk, hogy az „1” és „2” település között nincs is különbség, azaz ekvivalensek, persze csak strukturálisan, azaz kapcsolataik tekintetében. Ha a két települést ezentúl együtt akarjuk kezelni, akkor úgy emlegetjük őket, hogy az „1. blokk”. A „3”-mal jelölt központ egyedül is egy blokk, mert strukturálisan nincs más hozzá hasonló szereplő. Nevezzük „2. blokk”-nak. Végül a „4” és „5” településeket szívesen besorolnánk egy újabb blokkba, de a figyelmesebb szemlélő egy apró különbséget fedezhet fel köztük. Az ábra szerint a „4” településről járnak emberek az „5”-be dolgozni, de fordítva ez nem igaz.
A döntést, hogy egy blokkba soroljuk-e az egymáshoz hasonló helyzetű, de mégsem strukturálisan ekvivalens szereplőket, különböző algoritmusok segítik. Ezek közül az egyik legelterjedtebb, de nem feltétlenül minden helyzetben a „legjobb” algoritmus a CONCOR elemzés. A CONCOR eljárás a mátrix oszlopai és sorai között számol korrelációt, amelynek eredményeként egy korrelációs mátrixot kap. A korrelációs mátrix értékei 0 és 1 közötti értékek. Ezután a korrelációs mátrix sorai és oszlopai közt számol korrelációt, és így tovább. Az ismétlődések (iterációk) addig tartanak, amíg a sokadik korrelációs mátrix csak néhány alcsoportból (al-mátrixból) áll, amelynek elemei csak vagy 1 vagy -1 értékeket vesznek fel. Ezeket egy-egy blokknak tekinthetjük, és a továbbiakban így hivatkozunk rájuk. Nézzünk egy példát!
Ucinet programcsomag menüsorában válasszuk ki a Network – Roles and Positions – Structural – CONCOR parancsot, majd a megjelenő ablak felső sorában válasszuk ki a kívánt adatbázist.
Érdemes elgondolkodni azon, hogy hány blokkot szeretnénk eredményként kapni. A blokkok számát, akárcsak a hierarchikus klaszterelemzésnél a klaszterekét, előre kell meghatározni. CONCOR elemzésnél a blokkok számát az határozza meg, hogy hányszor bontjuk ketté (split) a blokkokat. Egy bontás eredményeképp két blokkot kapunk, két bontáskor négyet, háromkor hatot, és így tovább. Első olvasatra bizonyára egyszerű szabálynak tűnik, valószínűleg mégis sokan eltévesztik; erre utal, hogy a szoftverfejlesztők a „bontások maximális mélysége” kérdés mellé zárójelben odaírták: „nem a blokkoké!” (max. depth of splits (not blocks))
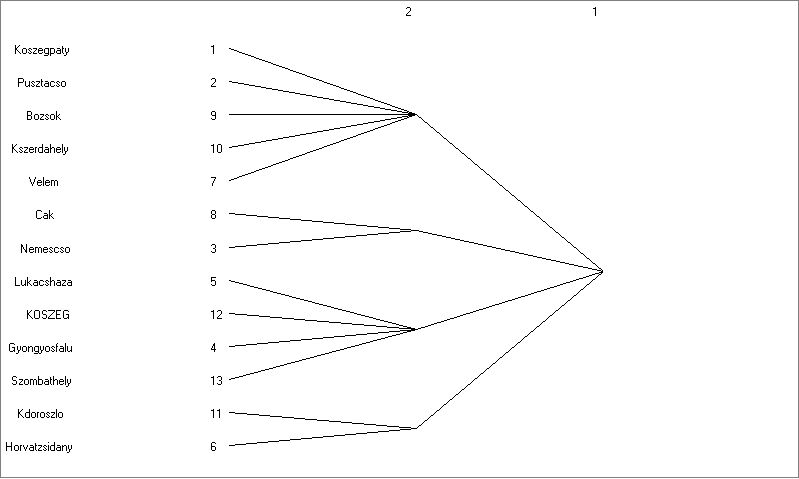
Végezzük el a CONCOR elemzést két, illetve három bontásban a szokásos adatmátrixunkon!
7.6. ábra. A Concor elemzés dendrogramjai 2, illetve 3 bontás után
Dendogram és a négy blokk elemei két bontás után
Dendogram és a hat blokk elemei három bontás után
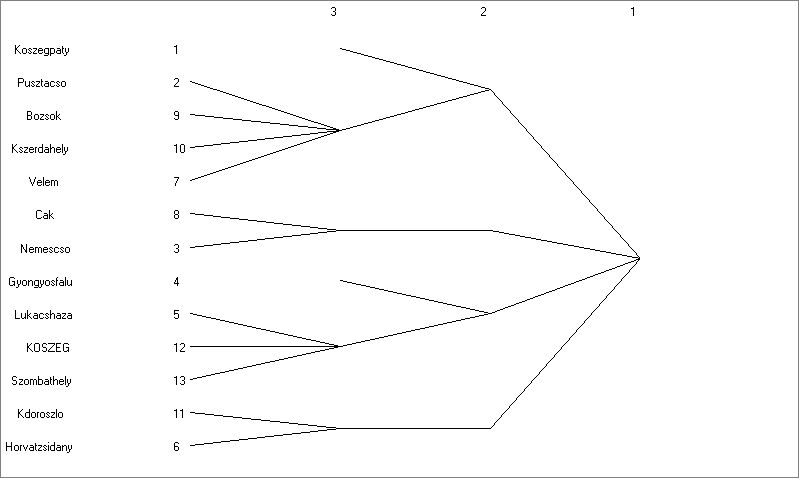
Hogy a hat vagy a négy blokkból álló felosztást választjuk-e, az ugyanúgy a kutató szabadsága, mint például a hierarchikus klaszterelemzésnél a csoportok számáról való döntés. Jelen esetben ténylegesen nincs értelme blokkokat készíteni, hiszen felesleges a 13 szereplős mátrixot 6 vagy négy elemesre csökkenteni. A példa kedvéért maradjunk a 6 blokkos felosztásnál. Itt világosan elkülönülnek az izolált pontok (2 db) és a nagy központiságú szereplők (Kőszeg, Szombathely, Lukácsháza). A CONCOR elemzés a következő adatokat adja ki:
CONCOR
--------------------------------------------------------------------------------
Diagonal: Reciprocal
Max partitions: 3
Input dataset: D:\...\KOSZMUN
Initial Correlation Matrix
1 2 3 4 5 6 7 8 9 10 11 12 13
Kosze Puszt Nemes Gyong Lukac Horva Velem Cak Bozso Kszer Kdoro KOSZE Szomb
----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
1 Koszegpaty 1.00 0.80 0.46 -0.06 0.43 0.00 0.80 0.46 0.68 0.80 0.00 -0.22 -0.18
2 Pusztacso 0.80 1.00 0.80 -0.07 0.22 0.00 1.00 0.80 0.85 1.00 0.00 -0.26 -0.21
3 Nemescso 0.46 0.80 1.00 -0.06 0.05 0.00 0.80 1.00 0.68 0.80 0.00 -0.22 -0.16
4 Gyongyosfalu -0.06 -0.07 -0.06 1.00 0.30 0.00 -0.07 -0.06 0.00 -0.07 0.00 0.30 0.37
5 Lukacshaza 0.43 0.22 0.05 0.30 1.00 0.00 0.22 0.05 0.14 0.22 0.00 0.65 0.47
6 Horvatzsidany 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00
7 Velem 0.80 1.00 0.80 -0.07 0.22 0.00 1.00 0.80 0.85 1.00 0.00 -0.26 -0.21
8 Cak 0.46 0.80 1.00 -0.06 0.05 0.00 0.80 1.00 0.68 0.80 0.00 -0.22 -0.16
9 Bozsok 0.68 0.85 0.68 0.00 0.14 0.00 0.85 0.68 1.00 0.85 0.00 -0.30 -0.24
10 Kszerdahely 0.80 1.00 0.80 -0.07 0.22 0.00 1.00 0.80 0.85 1.00 0.00 -0.26 -0.21
11 Kdoroszlo 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00
12 KOSZEG -0.22 -0.26 -0.22 0.30 0.65 0.00 -0.26 -0.22 -0.30 -0.26 0.00 1.00 0.82
13 Szombathely -0.18 -0.21 -0.16 0.37 0.47 0.00 -0.21 -0.16 -0.24 -0.21 0.00 0.82 1.00
PARTITION DIAGRAM
H
G o
K y S r
K s o L z v
o P z n u o K a
s u e N g k m d t
z s r e y a b o z
e z B d m o c K a r s
g t o a V e s s O t o i
p a z h e s f h S h s d
a c s e l C c a a Z e z a
t s o l e a s l z E l l n
y o k y m k o u a G y o y
1 1 1 1
Level 1 2 9 0 7 8 3 4 5 2 3 1 6
----- - - - - - - - - - - - - -
3 . XXXXXXX XXX . XXXXX XXX
2 XXXXXXXXX XXX XXXXXXX XXX
1 XXXXXXXXXXXXX XXXXXXXXXXX
Relation 1
Blocked Matrix
1 1 1 1
8 3 1 0 2 9 7 1 6 4 5 2 3
C N K K P B V K H G L K S
-------------------------------------
8 Cak | | | | | | 1 1 |
3 Nemescso | | | | | | 1 1 |
---------------------------------------
1 Koszegpaty | | | | | | 1 1 |
---------------------------------------
10 Kszerdahely | | | | | | 1 1 1 |
2 Pusztacso | | | | | | 1 1 1 |
9 Bozsok | | | | | 1 | 1 1 1 |
7 Velem | | | | | | 1 1 1 |
---------------------------------------
11 Kdoroszlo | | | | | | |
6 Horvatzsidany | | | | | | |
---------------------------------------
4 Gyongyosfalu | | | | | | |
---------------------------------------
5 Lukacshaza | | | | | | 1 1 |
12 KOSZEG | | | | | | |
13 Szombathely | | | | | | |
--------------------------------------
Density Matrix
1 2 3 4 5 6
----- ----- ----- ----- ----- -----
1 0.000 0.000 0.000 0.000 0.000 0.667
2 0.000 0.000 0.000 0.000 0.667
3 0.000 0.000 0.000 0.000 0.250 1.000
4 0.000 0.000 0.000 0.000 0.000 0.000
5 0.000 0.000 0.000 0.000 0.000
6 0.000 0.000 0.000 0.000 0.000 0.333
R-squared = 0.775
First order actor-by-actor correlation matrix saved as dataset Concor1stCorr
Partition-by-actor indicator matrix saved as dataset ConcorCCPart
Permutation vector saved as dataset ConcorCCPerm
----------------------------------------
Running time: 00:00:01
Output generated: 29 mar 04 06:07:29
Copyright (c) 1999-2004 Analytic Technologies
A sok adat közül az induló mátrix tulajdonképpen érdektelen. A partíciós diagramm viszont megmutatja, hogy mely szereplőket választott szét a program már a legelső lépésben (ezek között mutatkozik a legnagyobb különbség), melyeket a másodikban, és melyeket csak a harmadikban. A blokkokból álló mátrix azt mutatja, hogy az utolsó iteráció után hogy néztek ki a helyi értékek, amelyek alapján a blokkokat kialakítottuk. Számunkra a legfontosabb a legutolsó információ, a blokkok kapcsolatát mutató táblázat (density matrix). A blokkok kapcsolati mátrixa alapján felvázolható a kapcsolatháló egyszerűsített, blokkokból álló gráfja, amely jelen esetben így néz ki:
7.7. ábra: blokkok kapcsolatai: a napi ingázás egyszerűsített folyamata Kőszeg térségében
[1] Freeman, Linton M. 1979: Centrality in Social Networks: Conceptual Clarification. In: Social Networks 1:215-39.
[2] Bonacich, Phillip 1987: Power and Centrality: A Family of Measures. In: American Journal of Sociology 92: 1170–1182.
*****************************
Recenzió Barabási Albert László könyvéről
Barabási Albert László könyve a 2003-as esztendő egyik jelentős könyvsikere volt az Egyesült Államokban. A könyv alcíme szerint a kötetből megtudhatjuk, hogy “hogyan kapcsolódik minden mindenhez, és mit jelent ez a tudomány, az üzlet és a mindennapi élet számára”. A New Scientist-ben megjelent kritika (Cohen 2002)[4] szerint olyan szabályt fedeztek fel, amely egyaránt szabályozza szexuális életünket, a fehérjék működését és a filmsztárok világát. Ez a „mindenható” szabály a skálafüggetlenség.
A könyv üzenete röviden összefoglalva a következő: Erdős Pál és Rényi Alfréd nyomán a matematikusok sokáig elsősorban a véletlen gráfok vizsgálatával foglalkoztak. Barabási arra mutat rá, hogy a természetesen fejlődő rendszerekben a kapcsolatok nem véletlenül alakulnak ki, az újonnan érkezők jellemzően a korábbi központokhoz kapcsolódnak (v.ö. „kapcsolatérzékeny útfüggőség” Sik 2004[5]). A természetben és a társadalomban fellelhető legtöbb kapcsolatháló ezért hatványfüggvény eloszlású lesz. A fenti gondolatmenetből következik a skálafüggetlenség definíciója: „A véletlen hálózatokban a fokszámeloszlás csúcsa azt mutatja, hogy a pontok nagy részének ugyanannyi kapcsolata van és az átlagtól eltérő pontok rendkívül ritkák. Ezért a véletlen hálózatban a pontok fokszámának van egy jellemző nagysága, egy skálája, amelyet a fokszámeloszlási grafikon csúcsa határoz meg, és amelyet egy átlagos pont segítségével képzelhetünk el. Ezzel szemben a hatványfüggvény esetében az eloszlás csúcsának hiánya arra utal, hogy a valódi hálózatokban nincsen tipikus pont. A pontok folytonos hierarchiáját figyelhetjük meg, amely a kevés középponttól a sok pici pontig terjed. A legnagyobb középpontot két vagy három, valamivel kisebb középpont követi szorosan, majd egy tucat még kisebb következik, és így tovább, végül elérkezünk a sok kis pontig. A hatványfüggvény szerinti eloszlás tehát arra kényszerít bennünket, hogy teljesen lemondjunk a skála vagy a jellemző pont fogalmáról. (…) Ezekben a hálózatokban nincsen belső skála. Ezért kezdte csoportom skálafüggetlen hálózatként említeni a hatványfüggvény-eloszlású hálózatokat” (Barabási 2003: 6/2 láncszem).
Barabási és kutatócsoportja a skálafüggetlen rendszerek tulajdonságainak leírásával is foglalkozott. Legfontosabb megállapításuk a rendszer robosztusságára vonatkozik. „Egy (véletlen) hálózat csomópontjainak a meghibásodása a hálózatot könnyen széttördelheti elszigetelt, egymással nem kommunikáló részekre. (…) Skálafüggetlen hálózatból (viszont) véletlenszerűen eltávolítható a pontok jelentős része anélkül, hogy a hálózat széttöredezne. A skálafüggetlen hálózatok korábban nem sejtett hibatűrő képessége egy, a véletlen hálózatokétól eltérő tulajdonság. Mivel az Internetről, a világhálóról, a sejtről és az ismeretségi hálózatokról tudott, hogy skálafüggetlenek, ezek az eredmények azt jelzik, hogy a hibákkal kapcsolatban jól ismert ellenálló képességük topológiájuk belső tulajdonsága” (Barabási 2003: 9/2 láncszem). A robosztusság alapgondolata szerint tehát a néhány nagy forgalmú központ is egyben tartja a rendszert, ha a rendszer elemeinek nagy része véletlenszerűen megsemmisül. Szándékos támadásokkal szemben azonban ezek a rendszerek védtelenek: néhány központ kiiktatása után a rendszer máris elemire eshet szét. „Jó tudni, ha az ember ezekre a hálózatokra van utalva” – jegyzi meg Barabási, aki rámutat, hogy egyebek közt a társadalom és az emberi szervezet is skálafüggetlen kapcsolatháló.
[1] Kőszeg és vonzáskörzete kistérség 1998. Kézirat, készült a Vasi Reginnov Kft. megbízásából. Készítették Letenyei László, Vedres Balázs és Lénárd Henrik. A példa gyanánt legtöbbet hivatkozott adat egy kistérségi reprezentatív lakossági felmérésből származik.
[2] Az adatok a kistérségi lakosságra reprezentatív kérdőíves adatfelvételből származnak. A kérdést nyitott formában tettük fel (Ön hol dolgozik?), amelyet településnévvel kódoltunk, kivéve ha Ausztriában dolgozott, ekkor az országot. Ha válaszként munkahelyet mondtak, akkor visszakérdeztünk, hogy hol található a munkahely, és ugyanúgy a települést kódoltuk. Ha a válasz „itthon”, „tsz-ben”, „helyben” stb. volt, értelemszerűen annak a településnek kódoltuk, ahol elhangzott a válasz. Az eredmények tükrében a kistérség településein kívül csak Szombathely jelentett jelentős elszívó hatást, a többi célpont nem érte el azt a küszöböt, amely felett bevontuk volna az elemzésbe.
[3]Magyar Könyvklub, 2003. Eredeti megjelenés: Barabási Albert László: Linked. The New Science of Networks. Cambridge MA: Perseus Publishing, 2002.
[4] Cohen, David 2002: All The World is a Net. In: New Scientist, 2338: 2002. 04. 13.
[5] Sik, Endre 2004: Network Dependent Path-Dependence. Paper Presented at: 24. International Sunbelt Social Network Conference, Portoroz